Think of sync or all you sync will sink.
Not Dr. Seuss
Synchronization is a fundamental element of software development. It takes many forms, from forcing clocks on different devices to agree on just how late it is, to serializing access to resources in multithreaded programming with a @synchronized block.
In this article, I want to introduce various approaches to data synchronization, which I'll refer to from here on simply as sync. In short, the question is: how do you keep two data stores, separated by space and time, mirroring one another as closely as possible?
My own interest goes back to the early days of the iOS App Store, and sync has played a major role in how I've earned my living ever since. I am the developer of a study card application called Mental Case. With versions for Mac, iPad, and iPhone, Mental Case is more a suite than a single app, and one of its distinguishing features has always been the ability to sync up your study material and progress between devices. Originally, in the era of the digital hub, Mental Case would sync a central Mac over a local Wi-Fi network with one or more iOS devices. Currently, the Mental Case apps sync peer-to-peer via iCloud.
Properly implementing sync can be challenging, but it is a problem that is more specialized than developing a general web service, and this allows for more specialized solutions. For example, where a generic web service will invariably require server-side development, it is possible to adopt a synchronization framework with minimal changes to your existing codebase, and no server-side code at all.
In what follows, I want to introduce the various approaches to sync that have arisen since the early days of mobile devices, explain their workings at a high level, and give some guidance as to which would work best for your app. I'll also delineate the new trends in sync, which point to where we are heading.
A Brief History
Before looking at the various approaches to sync in detail, it's worth examining how it has evolved and adapted to the constraints imposed by the technology of the day.
As far as consumer devices are concerned, sync began with wired connections. In the late 1990s and early 2000s, peripheral devices such as the Palm Pilot and iPod would sync with a Mac or PC via Firewire or USB. Apple's Digital Hub strategy built upon this approach. Later, with network speeds increasing, Wi-Fi and Bluetooth supplemented the wire to some extent, but iTunes continues to use this approach today.
As cloud services took off later in the 2000s, the role played by the central Mac/PC shifted to the cloud. The cloud has the advantage that it is accessible whenever a device has a network, and it's always on. With cloud-based sync, there was no longer a need to be at home in the vicinity of your computer to sync.
Each of the approaches above utilizes what I'll term Synchronous Communication (SC) between devices. An app on your iPhone communicates directly with a Mac or cloud service, and it expects to receive a response in real time.
At present, we are seeing the rise of a new approach to sync, one that is built upon Asynchronous Communication (AC). Rather than 'talking' directly to the cloud, the app exchanges data with a framework or local file system. The app does not expect an immediate response; instead, data is transferred to and from the cloud in the background.
This approach decouples the application code from the sync process, freeing the developer from explicitly handling sync operations. Examples of products following this new direction are Apple's Core Data—iCloud framework, the Dropbox Datastore API, and even document stores like TouchDB (which is based on Apache's CouchDB project).
This history of sync does not follow a single linear path. Each stage overlaps with those that follow, continuing to be utilized even as new approaches evolve. Today, all of these techniques still exist and are in active use, and each may be an appropriate solution to your particular problem.
The Sync Grid
We've already seen that approaches to sync can be categorized according to whether they involve synchronous communications, but it is useful to break things down even further according to whether a 'smart' server is involved, or whether the process is essentially peer-to-peer, with the client apps handling all of the complexities. This leads to a simple grid into which all sync technologies fall:
| Synchronous | Asynchronous | |
| Client-Server |
Parse StackMob Windows Azure Mobile Services Helios Custom Web Service |
Dropbox Datastore TouchDB Wasabi Sync Zumero |
| Peer-to-Peer |
iTunes/iPod Palm Pilot |
Core Data with iCloud TICoreDataSync Core Data Ensembles |
The Synchronous Peer-to-Peer (S–P2P) approach was actually the first to be broadly adopted, and used for peripheral devices like iPods and PDAs. S-P2P tends to be simpler to implement, and local networks are fast. iTunes still uses this approach, due to the large quantities of media transfer involved.
 Synchronous Peer-to-Peer (S–P2P)
Synchronous Peer-to-Peer (S–P2P)
The Synchronous Client-Server (S-CS) approach grew in popularity as networks improved and cloud services like Amazon Web Services (AWS) became popular. S-CS is probably the most common approach to sync in use today. From a implementation standpoint, it is much the same as developing any other web service. Typically a custom cloud app is developed in a language, and with a programming stack unrelated to the client app, such as Ruby on Rails, Django, or Node.js. Communication with the cloud is slower than using a local network, but S-CS has the advantage of being 'always on,' and the client can sync from any location with network connectivity.
Synchronous Client-Server (S–CS)
With Asynchronous Client-Server (A-CS), the developer adopts an API for data storage, which gives access to a local copy of the data. Sync occurs transparently in the background, with the application code being informed of changes via a callback mechanism. Examples of this approach include the Dropbox Datastore API, and -- for Core Data developers -- the Wasabi Sync service.
One advantage of the asynchronous replicate and sync approach is that apps continue to work and have access to the user's data when the network is unavailable. Another is that the developer is less burdened with the details of communications and sync, and can focus on other aspects of the app, treating data storage almost as if it were local to the device.
Asynchronous Client-Server (A–CS)
The Asynchronous Peer-to-Peer (A-P2P) approach is still in its infancy, and has not seen widespread use. A-P2P places the full burden of piecing together the 'truth' on the client app, without any recourse to direct communication. Developing an A–P2P framework is complex, and that has led to some well-publicized failures, including early attempts by Apple to add iCloud support to Core Data (recent attempts are much improved). As with A–CS, each device has a full copy of the data store. The stores are kept in sync by communicating changes between devices via a series of files, typically referred to as transaction logs. The logs are moved to the cloud, and from there to other devices by a basic file handling server (e.g. iCloud, Dropbox), which has no insight into the file content.
Asynchronous Peer-to-Peer (A–P2P)
Given the complexities of developing an A-P2P system, you might ask why we should even bother. One major advantage of A-P2P frameworks is that they abstract away the need for an intelligent server. The developer can avoid all server-side development, and can take advantage of the multitude of file transfer services available, many of which are free. And because A-P2P systems are not coupled to a particular service, there is no danger of being locked in to a single vendor.
The Elements of Sync
Having introduced the different families of sync algorithms, I now want to take a look at the common components of these algorithms. What do you have to consider over and above what you would need to handle in an isolated app?
There are a few elements that all sync methods have in common. These include:
-
Identifying corresponding objects across stores
-
Determining what has changed since the last sync
-
Resolving conflicts due to concurrent changes
In the sections that follow, I want to address each of these, before moving on to explain in more detail how you would go about implementing the algorithms.
Identity
In standalone apps, with a single store, objects are typically identified by a row index in a database table, or something equivalent like an NSManagedObjectID in Core Data. These identities are specific to the store, and not suitable for identifying corresponding objects on different devices. When an app syncs, it's important that objects in different stores can be correlated with one another, hence the need for global identifiers.
Global identifiers are often just Universally Unique Identifiers (UUIDs); objects in different stores with the same global identifier are considered to be logically representative of a single instance. Changes to one object should eventually result in the corresponding object also being updated. (UUIDs can be created in Cocoa with the recently added NSUUID class, or the oft-forgotten globallyUniqueString method of the NSProcessInfo class.)
UUIDs are not appropriate for all objects. For example, it is not unusual to have certain classes of objects for which there are a fixed set of members to choose from. A common example is a singleton object, for which only one possible object is allowed. Another example is that of tag-like objects, where uniqueness is determined by a string.
However a class determines object identity, it is important that it is reflected in the global identifiers. Logically equivalent objects in different stores should have the same identifier, and objects that are not equivalent should have different identifiers.
Change Tracking
Change Tracking is a term used to describe how a sync algorithm determines what has changed since the last synchronization event, and thereby what should be changed locally. Each change to an object (often called a delta) is usually handled as a CRUD operation: a creation, read, update, or deletion.
One of the first choices that needs to be made is the granularity that the recorded changes will take. Should all properties in an entity be updated if any single property changes? Or should only the changed property be recorded? The right path may vary; I'll discuss this more as we delve into details.
In either case, you need a means to record a change. In the simplest case, this could just be a Boolean attribute in the local store, indicating whether the object is new or has been updated since the last sync. In a more advanced algorithm, a change could be stored outside the main store as a dictionary of changed properties and with an associated timestamp.
Conflict Resolution
When you have two or more stores representing the same logical set of data, the potential for conflicts exists. A change to an object in one store could occur at about the same time as a change to the corresponding object in a second store, with no intervening sync. These changes are said to have occurred concurrently, and some action may be necessary to leave the conflicting objects in a consistent and valid state across all stores once they sync up.
In the simplest of all worlds, reading and writing a store can be considered an atomic operation, and resolving conflicts simply involves choosing which version of the store to keep. This is actually more common than you might think. For example, the document-syncing capabilities of iCloud are handled this way: when a conflict arises, the user is asked to choose the version he or she wishes to keep -- changes from the conflicting stores are not merged.
There are many ways to decide which changes take precedence when resolving conflicts. If a central server is involved, the most straightforward approach is just to assume the latest sync operation takes priority. Any change present in the operation overwrites previously stored values. More complex systems involve comparing the creation timestamps of conflicting changes and keeping the most recent.
Conflict resolution can get tricky, and if you have the choice, you should avoid it altogether by devising a model that simply cannot become invalid due to concurrent changes. In a new project, this is much easier than trying to think of all the possible invalid states that could arise.
Relationships can be particularly troublesome (and that's not a commentary on human interactions). Take a simple one-to-one relationship between entities A and B. Imagine Device 1 and Device 2 both begin with object A[1] related to object B[1]. Device 1 creates an object B[2], relates A[1] to B[2], and deletes B[1]. Concurrently, Device 2 also deletes B[1], but creates B[3] and relates that to A[1].
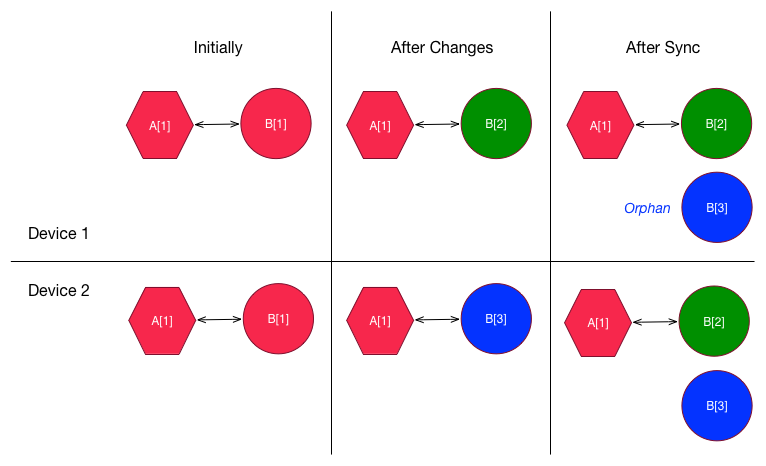
Orphaned object arising from conflicting changes to a one-to-one relationship.
After synchronizing, there will be an extra, orphaned B object that is unrelated to any A. If there were to be a validation rule requiring the relationship, you would now have an invalid object graph. And this is about the simplest type of relationship you can imagine. There are many other twists and turns possible when relationships are involved.
However conflicts like this are resolved, it is important that the resolution be deterministic. If the same scenario occurs on two different devices, they should end up taking the same action.
This may seem obvious, but it is very easy to get wrong. Take the example above. If your resolution involves randomly picking one of the B objects to delete, at some point the two devices are going to delete different objects, and you will end up with no B objects at all. You should strive to delete corresponding B objects from each device. This can be achieved by sorting the objects first, and always picking the same object.
Synchronous Communication, Peer-to-Peer (S-P2P)
Now that we have covered common elements of all sync algorithms, let's finish off by looking at the specific approaches introduced earlier in more detail, beginning with SC methods.
Let's start with the simplest workable S–P2P solution imaginable. Assume we have a Mac app like iTunes, which communicates synchronously with an iPhone via USB, Bluetooth, or Wi-Fi. With a fast local network, we don't have to be so concerned about restricting data transfer, so we can be lazy in that respect.
The first time a particular iPhone syncs, the two apps discover each other via Bonjour, and the Mac app zips up its entire store, sending the resulting file to the iPhone app via a socket, which would unzip and install it.
Now imagine the user takes the iPhone and makes changes to an existing object (e.g. gives a star rating to a song). The app on the device sets a Boolean flag on the object to indicate it is new or updated (e.g. changedSinceSync).
When the next sync occurs, the iPhone app zips and sends its entire data store back to the Mac. The Mac loads the store, looks for modified instances, and updates its own data accordingly. The Mac then sends back a full copy of its updated store, replacing the existing iPhone store, and the whole process starts over again.
There are many variations and improvements possible, but this is a working solution, and will be sufficient for many apps. To summarize, a sync operation involves one device transferring its store to another device, which determines what has changed, merges, and sends back the resulting store. You are guaranteed that both devices have the same data after a sync, so it is very robust.
Synchronous Communication, Client-Server (S-CS)
Things get more subtle when a server is added to the equation. The server offers flexibility, in terms of where and when a sync can occur, but it has a cost in terms of data transfer and storage. We need to reduce the communications overhead as much as possible, so copying whole stores back and forth is not going to fly.
Again, I'll aim for the simplest viable solution. Assume data is stored in a database on the server, with a last-modified timestamp for each object. When a client app first syncs, it downloads all the data in a serialized form (e.g. JSON), and builds a local store from it. It also records the timestamp of the sync locally.
As changes are made in the client app, it updates the last-modified timestamps of the objects involved. The server does the same thing, should another device sync in the interim.
When the next sync takes place, the client determines which objects have changed since the last sync, and only sends those objects to the server. The server merges in these changes. Where the server's copy of an object has been modified by another client, it keeps the change with the most recent timestamp.
The server then sends back any changes it has that are newer than the last sync timestamp sent by the client. This set should take account of the merge, with any overridden changes removed.
There are many variations possible. For example, you could include a timestamp for each individual property, and track changes at that level of granularity. Or you could do all merging of data on the client, and push merge changes back to the server, effectively switching roles. But fundamentally, one device sends changes to the other, and the receiver merges and sends back a set of changes incorporating the results of the merge.
Deletions require a little more thought, because once you delete an object, you have no way to track it. One option is to use soft deletions, where the object is not really deleted, but marked for deletion (e.g. using a Boolean property). (This is analogous to trashing a file in the Finder. It only gets permanently removed when you empty the trash.)
Asynchronous Communication, Client-Server Sync (A-CS)
The attraction of asynchronous sync frameworks and services is that they offer an off-the-shelf solution. The synchronous solutions discussed above are bespoke — you have to write lots of custom code for each app. What's more, with an S-CS architecture, you have to duplicate similar functionality across all platforms, and maintain operation of a server. This requires a skill set that most Objective-C developers don't possess.
Asynchronous services (e.g. Dropbox Datastore API and Wasabi Sync) typically provide a framework, which the app developer uses as if it were a local data store. The framework stores its changes locally, and then handles syncing with a server in the background.
The main difference between A–CS and S-CS is that the extra layer of abstraction provided by the framework in A–CS shields the client code from direct involvement in syncing. It also means that the same service can be used for all data models, not just one particular model.
Asynchronous Communication, Peer-to-Peer Sync (A-P2P)
A-P2P is the most underdeveloped approach, because it is also the most difficult to implement. But its promise is great, as it goes a step beyond A-CS, abstracting away the backend so that a single app can sync via a multitude of different services.
Underdeveloped as it is, there are apps already using this approach. For example, the popular To-Do list Clear has a custom implementation of A-P2P, which syncs via iCloud, and has been documented online. And frameworks like Apple's Core Data—iCloud integration, TICoreDataSync, and Core Data Ensembles all take this approach and are gradually finding adoption.
As an app developer, you shouldn't have to concern yourself too much with how an A-P2P system works — the complexities should remain largely hidden — but it is worth understanding how things work at a basic level, as well as the challenges involved.
In the simplest case, each device writes its CRUD change sets to transaction log files, and uploads them to the cloud. Each change set includes an ordering parameter, such as a timestamp, and when a device receives new changes from other devices, it replays them to build up a local copy of the store.
If each device just kept writing transaction logs, data in the cloud would increase ad infinitum. A rebasing technique can be employed to compress old change sets and set a new baseline. Effectively, all old changes are reduced to a set of object creations representing the initial state of the store. This reduces the number of redundant changes stored in the history. For example, if an object gets deleted, all changes related to that object can be removed.
A-P2P is Hard
This brief description probably makes it seem like a straightforward algorithm, but it hides many, many complexities. A-P2P is hard -- even harder than other forms of sync.
One of the biggest risks of A-P2P is divergence. With no central truth, and no direct communications between devices, a poor implementation can easily introduce small discrepancies which grow over time. (Bet you never expected to have to deal with The Butterfly Effect as an app developer.)
A-P2P wouldn't be as difficult if you could keep the latest copy of the whole store permanently in the cloud. But copying the store every save would require much too much data transfer, so A-P2P apps have to be content with receiving data in chunks, and they never know for sure what other data or devices exist at any point in time. Changes can even arrive out of order, or get changes from one device that are predicated on changes from a different device that haven't arrived yet. You can literally expect to see updates to an object that hasn't been created yet.
Not only can changes arrive out of order, but even determining what that order is can be challenging. Timestamps usually can't be trusted, especially on client devices like iPhones. If you aren't careful, and accept a timestamp way into the future, it could prevent new changes ever being incorporated again. More robust approaches to ordering events in time are available (e.g. Lamport Timestamps and Vector Clocks), but at a cost: ordering of events in time is only approximate.
Details like these, and many others, make A-P2P sync a challenge to implement. But that doesn't mean we shouldn't try. The payoff — a backend-agnostic synchronizing store — is a worthy goal, and would make the barrier to implementing sync in apps much lower.
A Solved Problem?
I sometimes hear people say sync is a solved problem. I wish it were as easy as that makes it sound, because then every app would support sync out of the box. In reality, very few actually do. It would perhaps be more accurate to say that sync has solutions, most of which are challenging to adopt, expensive, or limiting in some way.
We've seen that data synchronization algorithms take many different forms, and there really is no ideal one-size-fits-all approach. The solution you adopt will depend on the needs of your app, your resources, and your skills as a developer.
Does your app work with very large quantities of media data? Unless you are a cash-rich startup, you will probably be best served by good old-fashioned S-P2P over a local network, like iTunes.
Have a simple data model and ambitions to extend into social or go cross platform? S-CS with a custom web service is probably the way to go.
Developing a new app, where the ability to sync anywhere is paramount, but you don't want to waste too much time on it? Adopt an A-CS solution like the Dropbox Datastore API.
Or do you have an existing Core Data app, don't want to mess with servers, and don't want to get locked in to one vendor? An A-P2P solution like Ensembles may be your best option. (Admission: I am the founder and principle developer of the Ensembles project.)
Choose wisely.